At explai, we love being part of Berlin's tech community — learning from practitioners, sharing what we've built, and pushing the conversation on what AI agents can do for enterprise data. In early 2026 we did exactly that at two events: PyData Berlin in January and AI Tinkerers Berlin in March, where Dirk presented Agentic Data Science Patterns to packed rooms.

Here's what the talk covered.
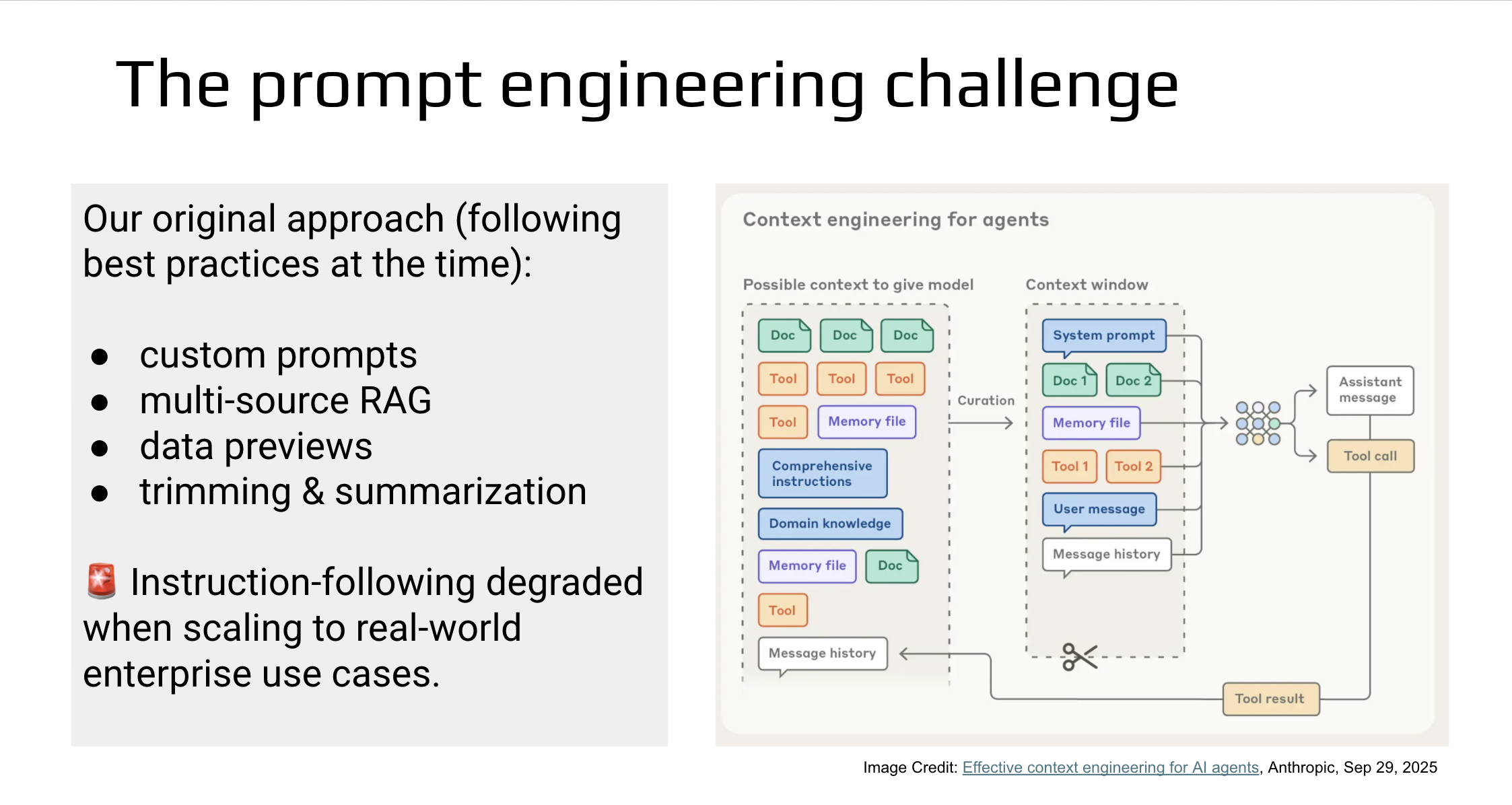
The Prompt Engineering Challenge
Building a data agent that works in demos is straightforward. The difficulty starts when you scale to real enterprise environments: evolving schemas, domain-specific metrics, and complex multi-source data. The original approach — custom prompts, multi-source RAG, data previews, and trimming — hit a wall when instruction-following degraded under the weight of everything crammed into the context window.
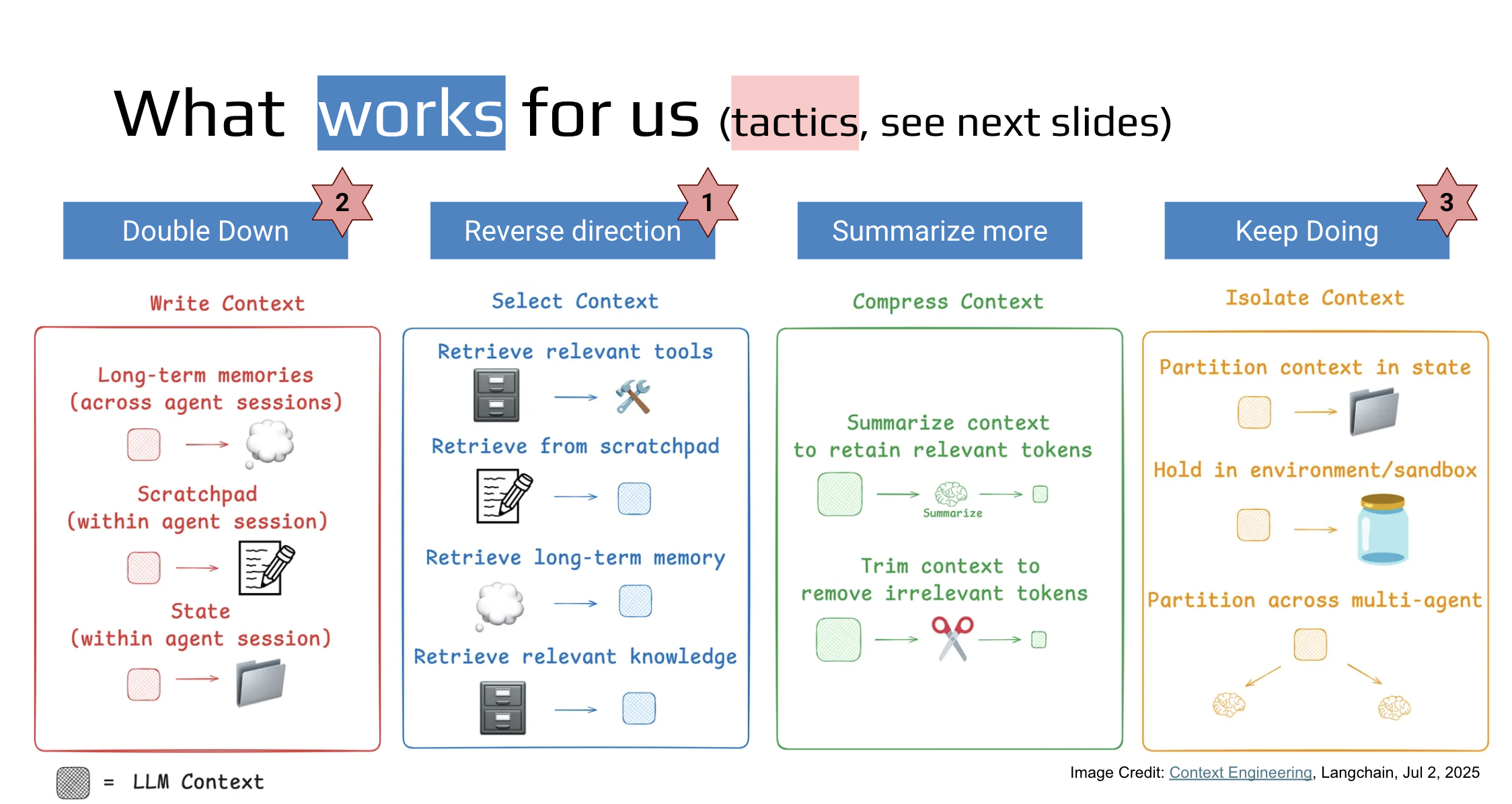
What Works: Four Strategies
Four context management strategies address this: Write Context (persist long-term memory and scratchpad), Select Context (retrieve only what's relevant), Compress Context (summarize and trim), and Isolate Context (partition across agents or environments). Three concrete tactics put these into practice.
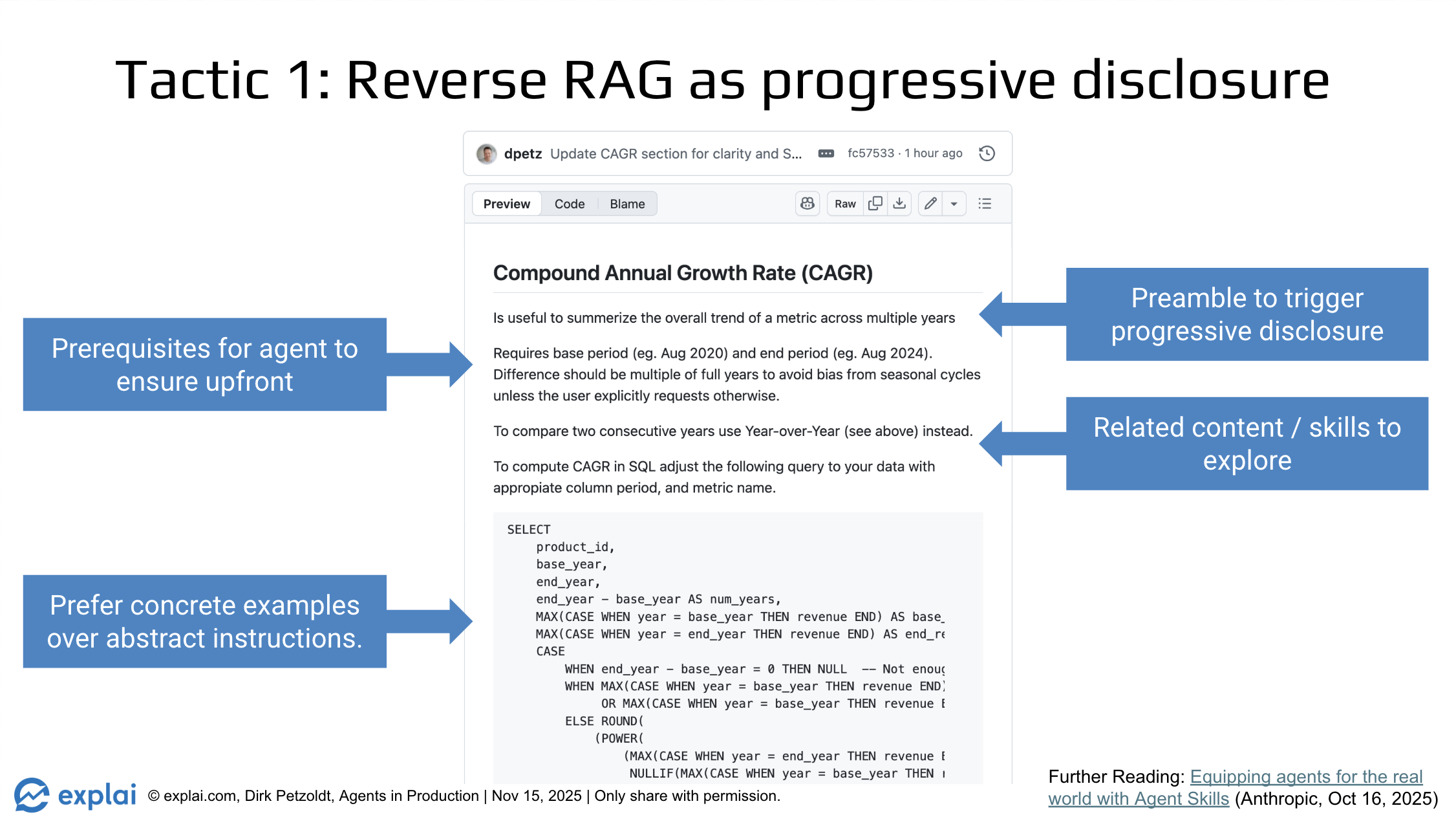
Tactic 1: Reverse RAG as Progressive Disclosure
Instead of front-loading a flat blob of documentation, the agent retrieves structured "skill" documents with a preamble, prerequisites, related content, and concrete SQL examples — reading just enough to orient itself, then fetching deeper detail on demand.
Tactic 2: Write Context Using Artifacts
Rather than repeating schema details every turn, the agent writes structured <table_artifact> tags encoding table identity, endpoints, statistics, and lineage into the conversation state — keeping context compact while giving the model a stable reference.

Tactic 3: Isolate Context via Code Sandbox
Generated charts, tables, and intermediate data objects stay in the execution environment rather than flowing back into the context window. The agent writes Python to a sandbox, gets back variable names and stdout, and the frontend renders artifact URIs — keeping large objects out of the prompt entirely.

Want to see how explai applies these patterns to your data? Get in touch.